Langchain integration (Python)
Langfuse integrates with Langchain using the Langchain Callbacks (opens in a new tab). Thereby, the Langfuse SDK automatically creates a nested trace for the abstractions offered by Langchain.
Add the handler as a callback when running your Langchain model/chain/agent:
# Initialize Langfuse handler
from langfuse.callback import CallbackHandler
handler = CallbackHandler(PUBLIC_KEY, SECRET_KEY)
# Setup Langchain
from langchain.chains import LLMChain
...
chain = LLMChain(llm=llm, prompt=prompt, callbacks=[handler])
# Add Langfuse handler as callback
chain.run(input="<user_input", callbacks=[handler])Langchain expression language (LCEL)
chain.invoke(input, config={"callbacks":[handler]})In case of missing events or tokens:
There are two ways to integrate callbacks into Langchain:
- Constructor Callbacks: Set when initializing an object, like
LLMChain(callbacks=[handler])orChatOpenAI(callbacks=[handler]). This approach will use the callback for every call made on that specific object. However, it won't apply to its child objects, making it limited in scope. - Request Callbacks: Defined when issuing a request, like
chain.run(input, callbacks=[handler])andchain.invoke(input, config={"callbacks":[handler]}). This not only uses the callback for that specific request but also for any subsequent sub-requests it triggers.
For comprehensive data capture especially for complex chains or agents, it's advised to use the both approaches, as demonstrated above docs (opens in a new tab).
The Langfuse CallbackHandler tracks the following actions when using Langchain:
- Chains:
on_chain_start,on_chain_end.on_chain_error - Agents:
on_agent_start,on_agent_action,on_agent_finish,on_agent_end - Tools:
on_tool_start,on_tool_end,on_tool_error - Retriever:
on_retriever_start,on_retriever_end - ChatModel:
on_chat_model_start, - LLM:
on_llm_start,on_llm_end,on_llm_error
Missing some useful information/context in Langfuse? Join the Discord or share your feedback directly with us: feedback@langfuse.com
Notebook Setup
1. Initializing the Langfuse Callback handler
The Langfuse SDKs are hosted on the pypi index.
%pip install langfuse langchain openai --upgradeInitialize the client with api keys and optionally your environment. In the example we are using the cloud environment which is also the default.
Alternatively, you can also pass them as arguments to the CallbackHandler constructor.
import os
# Get keys for your project from the project settings page
# https://cloud.langfuse.com
os.environ["LANGFUSE_PUBLIC_KEY"] = ""
os.environ["LANGFUSE_SECRET_KEY"] = ""
# Your openai key
os.environ["OPENAI_API_KEY"] = ""
# Your host, defaults to https://cloud.langfuse.com
# For US data region, set to "https://us.cloud.langfuse.com"
# os.environ["LANGFUSE_HOST"] = "http://localhost:3000"from langfuse.callback import CallbackHandler
handler = CallbackHandler()# checks the SDK connection with the server.
handler.auth_check()2. Langchain
# further imports
from langchain.llms import OpenAI
from langchain.chains import LLMChain, SimpleSequentialChain
from langchain.prompts import PromptTemplate
from langfuse.callback import CallbackHandlerExamples
1. Sequential Chain
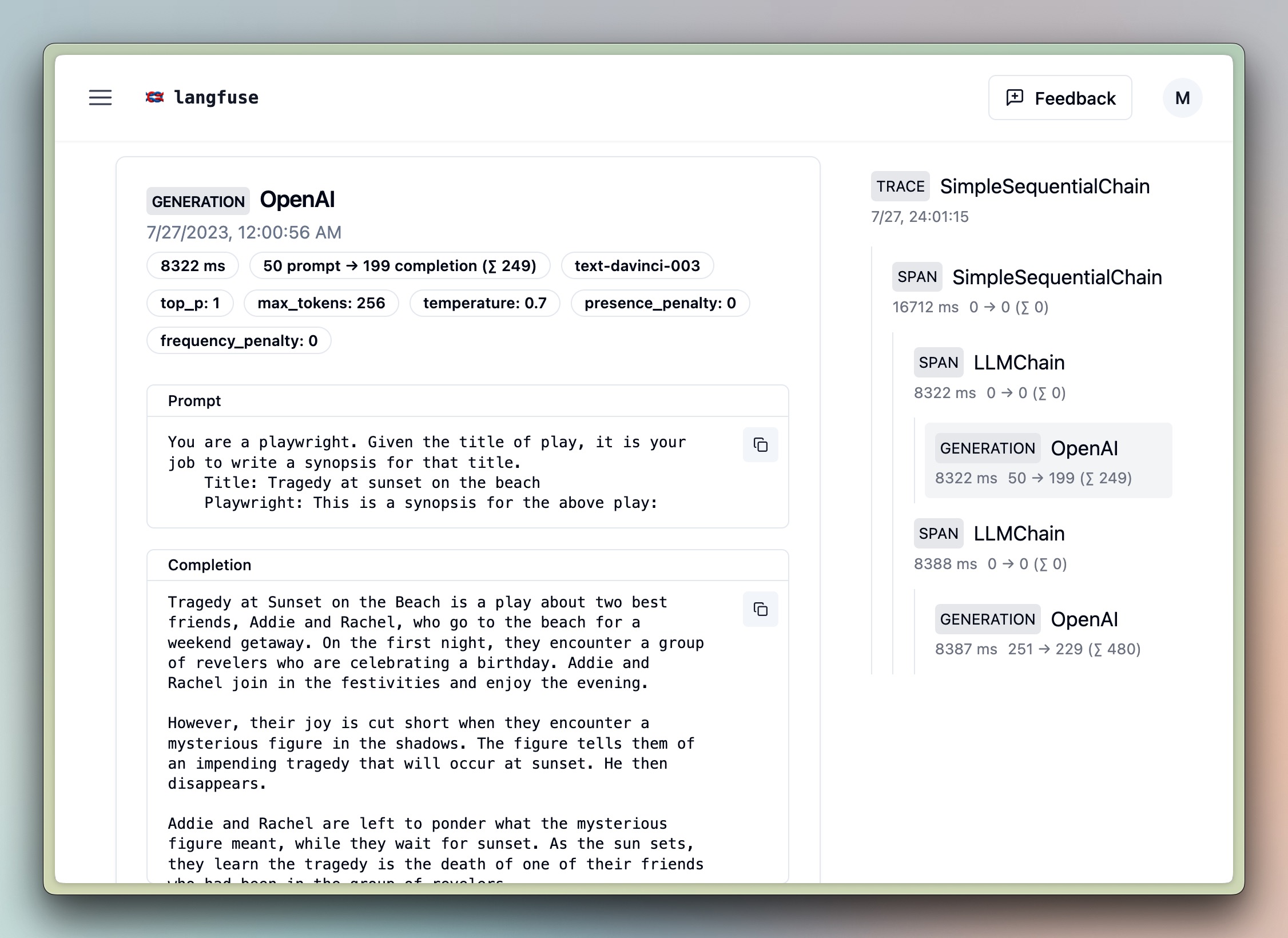
llm = OpenAI()
template = """You are a playwright. Given the title of play, it is your job to write a synopsis for that title.
Title: {title}
Playwright: This is a synopsis for the above play:"""
prompt_template = PromptTemplate(input_variables=["title"], template=template)
synopsis_chain = LLMChain(llm=llm, prompt=prompt_template)
template = """You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.
Play Synopsis:
{synopsis}
Review from a New York Times play critic of the above play:"""
prompt_template = PromptTemplate(input_variables=["synopsis"], template=template)
review_chain = LLMChain(llm=llm, prompt=prompt_template)
overall_chain = SimpleSequentialChain(
chains=[synopsis_chain, review_chain],
)
review = overall_chain.run("Tragedy at sunset on the beach", callbacks=[handler]) # add the handler to the run method
handler.langfuse.flush()2. Sequential Chain in Langchain Expression Language (LCEL)
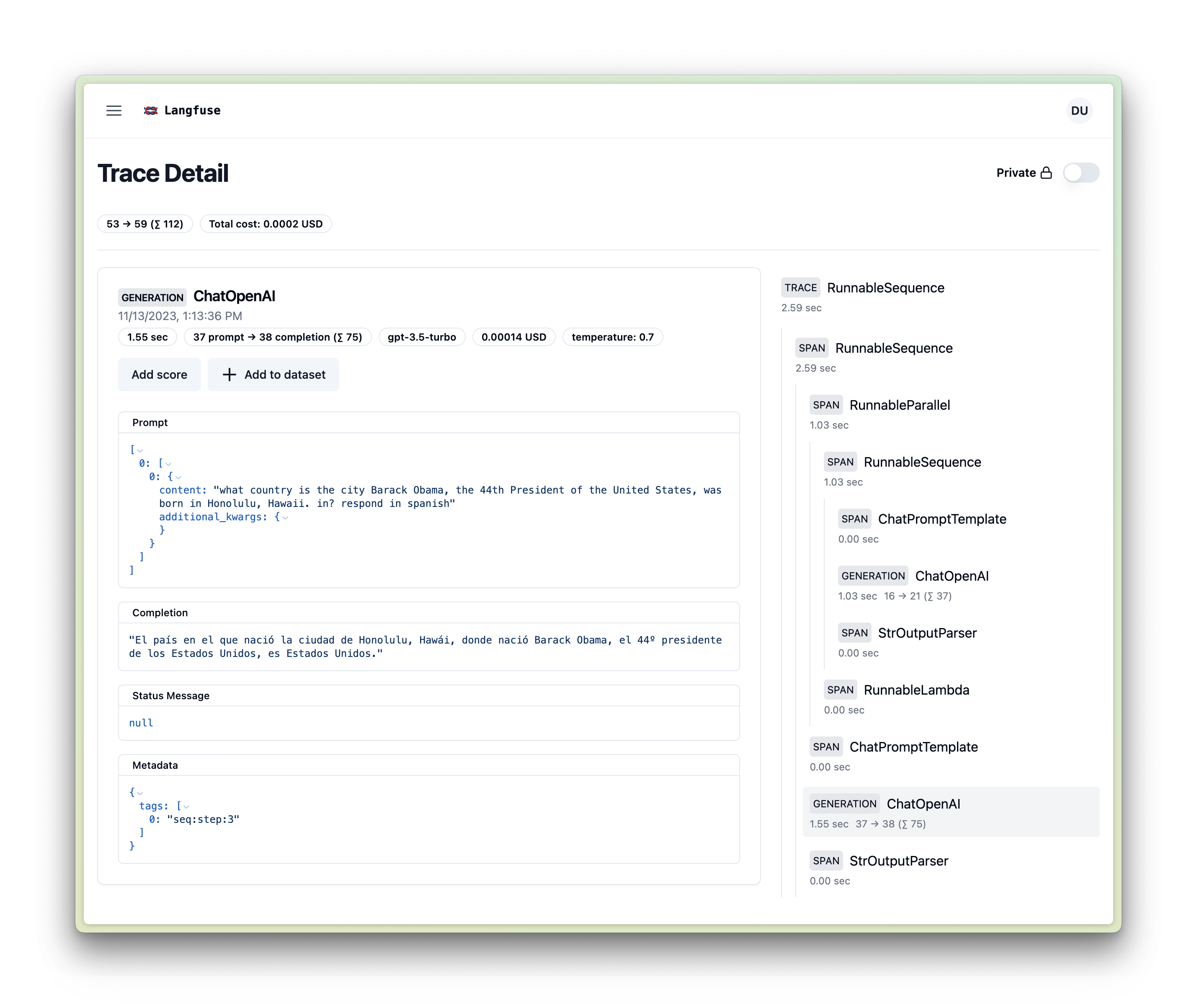
from operator import itemgetter
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser
handler = CallbackHandler()
prompt1 = ChatPromptTemplate.from_template("what is the city {person} is from?")
prompt2 = ChatPromptTemplate.from_template(
"what country is the city {city} in? respond in {language}"
)
model = ChatOpenAI()
chain1 = prompt1 | model | StrOutputParser()
chain2 = (
{"city": chain1, "language": itemgetter("language")}
| prompt2
| model
| StrOutputParser()
)
chain2.invoke({"person": "obama", "language": "spanish"}, config={"callbacks":[handler]})
handler.get_trace_url()3. QA Retrieval
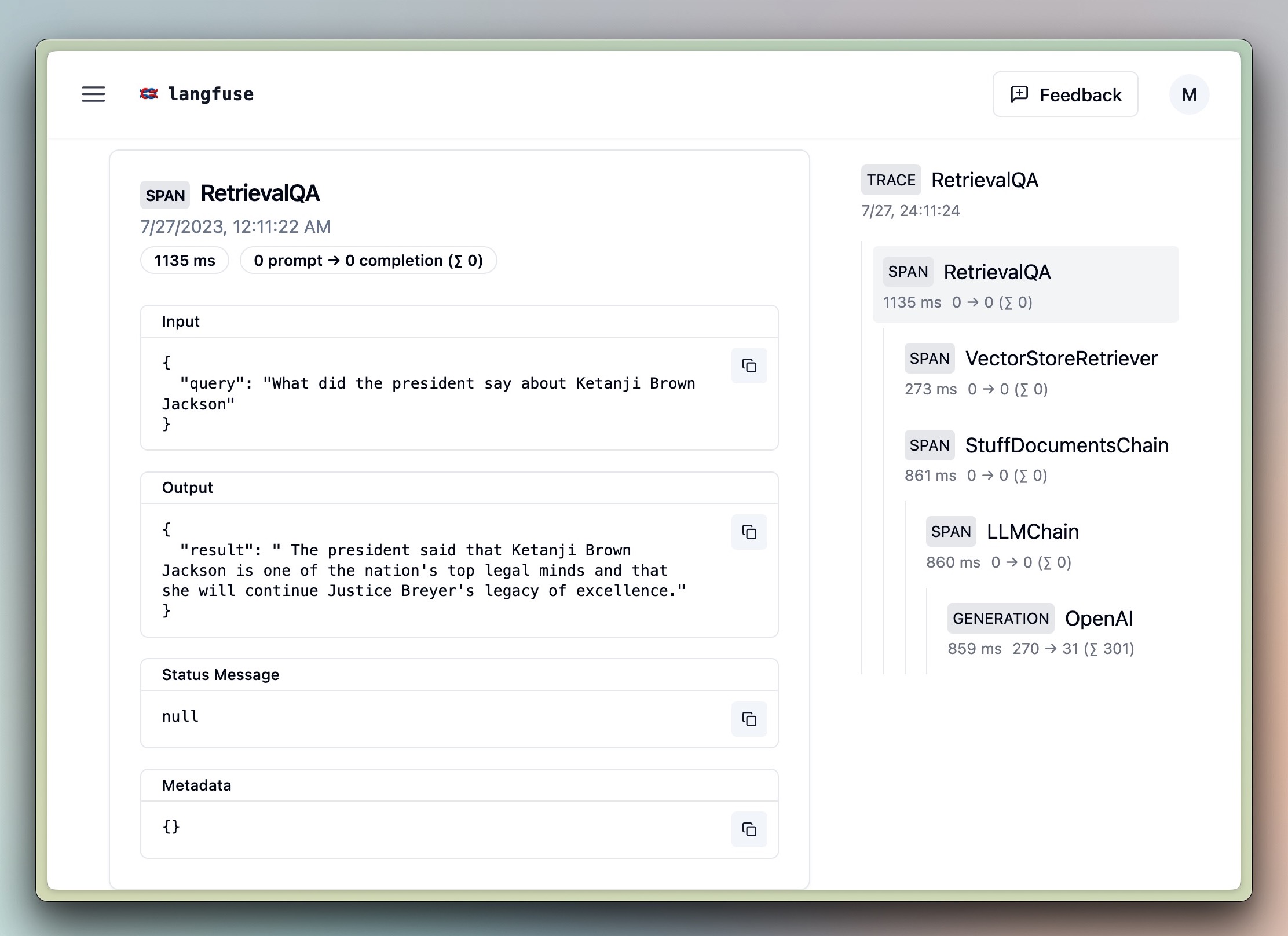
import os
os.environ["SERPAPI_API_KEY"] = ''%pip install unstructured chromadb tiktoken google-search-results python-magic --upgradefrom langchain.document_loaders import UnstructuredURLLoader
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.chains import RetrievalQA
handler = CallbackHandler()
urls = [
"https://raw.githubusercontent.com/langfuse/langfuse-docs/main/public/state_of_the_union.txt",
]
loader = UnstructuredURLLoader(urls=urls)
llm = OpenAI()
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_documents(texts, embeddings)
query = "What did the president say about Ketanji Brown Jackson"
chain = RetrievalQA.from_chain_type(
llm,
retriever=docsearch.as_retriever(search_kwargs={"k": 1}),
)
result = chain.run(query, callbacks=[handler])
print(result)
handler.langfuse.flush()
from langchain.agents import AgentType, initialize_agent, load_tools
handler = CallbackHandler()
llm = OpenAI()
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
result = agent.run("Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?", callbacks=[handler])
handler.langfuse.flush()
print("output variable: ", result)Adding scores
To add scores to traces created with the Langchain integration, access the traceId via handler.get_trace_id()
Example
from langfuse import Langfuse
from langfuse.model import CreateScore
from langfuse.model import CreateScoreRequest
# Trace langchain run via the Langfuse CallbackHandler as shown above
# Get id of created trace
traceId = handler.get_trace_id()
# Add score, e.g. via the Python SDK
langfuse = Langfuse()
trace = langfuse.score(
CreateScoreRequest(
traceId=traceId,
name="user-explicit-feedback",
value=1,
comment="I like how personalized the response is"
)
)Adding trace as context to a Langchain handler
It is also possible to generate a Langchain handler based on a trace. This can help to add context such as a specific user_id, name`` or metadata`. All the Langchain observations will be collected on that trace.
To do that, we first need to initialize the Python SDK, create a trace, and finally create the handler.
import uuid
import os
from langfuse.client import Langfuse
from langfuse.model import CreateTrace
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
langfuse = Langfuse()
trace = langfuse.trace(CreateTrace(name="synopsis-application", user_id="user-1234"))
handler = trace.get_langchain_handler()
llm = OpenAI()
template = """You are a playwright. Given the title of play, it is your job to write a synopsis for that title.
Title: {title}
Playwright: This is a synopsis for the above play:"""
prompt_template = PromptTemplate(input_variables=["title"], template=template)
synopsis_chain = LLMChain(llm=llm, prompt=prompt_template)
synopsis_chain.run("Tragedy at sunset on the beach", callbacks=[handler])
langfuse.flush()Configuring multiple runs per trace
Sometimes it is required to have multiple Langchain runs in one 'Trace'. For this, we provide the 'setNextSpan' function to configure the 'id' of the parent span of the next run. This can be helpful to create scores for the different runs.
The example below will result in the following trace:
TRACE (id: trace_id)
|
|-- SPAN: LLMCain (id: generated by Langfuse)
| |
| |-- GENERATION: OpenAI (id: generated by Langfuse)
|
|-- SPAN: LLMCain (id: generated by 'next_span_id')
| |
| |-- GENERATION: OpenAI (id: generated by Langfuse)import uuid
import os
from langfuse.client import Langfuse
from langfuse.model import CreateTrace
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
langfuse = Langfuse()
trace_id = str(uuid.uuid4())
trace = langfuse.trace(CreateTrace(id=trace_id))
handler = trace.get_langchain_handler()
llm = OpenAI()
template = """You are a playwright. Given the title of play, it is your job to write a synopsis for that title.
Title: {title}
Playwright: This is a synopsis for the above play:"""
prompt_template = PromptTemplate(input_variables=["title"], template=template)
synopsis_chain = LLMChain(llm=llm, prompt=prompt_template)
synopsis_chain.run("Tragedy at sunset on the beach", callbacks=[handler])
# configure the next span id
next_span_id = str(uuid.uuid4())
handler.setNextSpan(next_span_id)
synopsis_chain.run("Comedy at sunset on the beach", callbacks=[handler])
langfuse.flush()